
Package management at scale with Landscape

Free Ekanayaka
on 22 April 2015
Tags: Landscape
This post describes the design and implementation of a micro-service written in Go that has made it possible to massively scale Landscape’s package management features, supporting package-related queries across tens of thousands of registered systems.
The feature
The package management section in the Landscape web UI allows you to easily perform package-related queries across all your registered systems (or a selection of them). This is possible because the Landscape clients running on such systems regularly send to the server information about the state of all available and installed packages. For example, the screenshot below shows that I currently have two computers with security updates available, three with regular upgrades available, one with “on hold” packages (i.e. packages that won’t be upgraded even if they have an upgrade available, see here) and finally one which is up-to-date.

If I click on the link about security upgrades, I can see further details telling me which packages at which versions are upgradable on which systems. For example, in the following screenshot I’m presented a list of package names, each of which has a security upgrade available on one or more of the selected systems. I can expand a package name to see exactly which version is upgradable, as I did for the apache2 package. If I had more computers with apache2 security upgrades of different versions, the expanded block would have extra lines for those versions. Or if more computers had the same apache2 version, they would be aggregated on the same line.
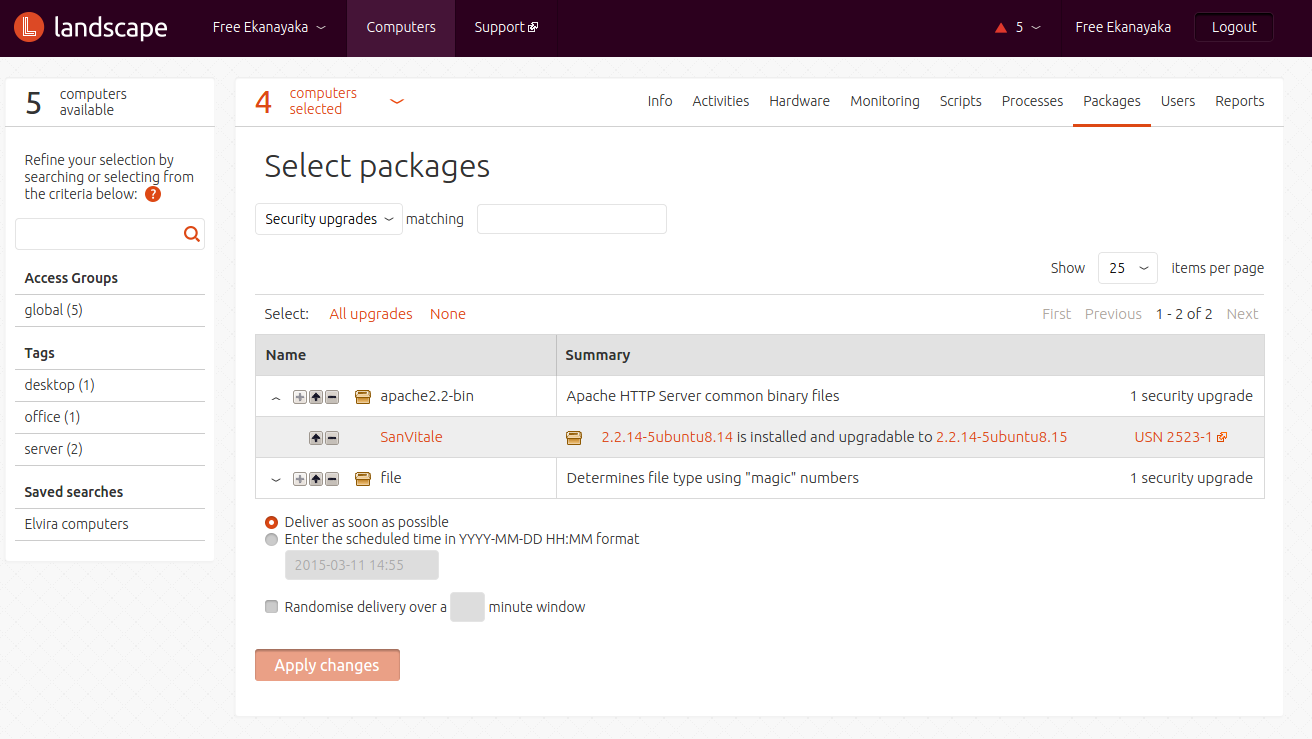
I could now select one or more security upgrades and apply them (the server would send a message to the relevant clients telling them to perform those upgrades). Since there are a number of package search criteria available in Landscape, instead of looking up all security upgrades available on the selected systems, I could, for instance, search for a certain package across the ones installed on the selected systems, or across all the ones available in the APT sources of those systems, and so on. I would be presented with a UI similar to the one above, listing the matches one per line and allowing the user to expand a certain line to see more details.
A lot of data
The package information about registered computers is kept in a PostgreSQL database, using a denormalized schema: a single table holds one row per computer, sporting four intarray columns each storing the list of package IDs that are reported by the client to be in certain state (available, upgrades, installed, held). The first implementation of the package search feature was written in Python and for each web UI HTTP request it would load the package ID arrays of all involved computers and perform the relevant data filtering and aggregation in the application. Unfortunately this resulted in poor scalability. A benchmark showed that in order to perform a package search query across 3000 computers the system took 102 seconds on modern hardware. The reason discovered was that besides the quite significant overhead of loading all computer package data from the database, that approach required the system to fully scan all available package data for all computers in the query. To give an idea of the bare cost of scanning such a data set, if we have 50,000 computers and each of them has about 40,000 available packages, then that’s about 2 billion memory accesses, which takes in the order of 50 seconds using modern hardware. The takeaway was that any solution that wanted to scale must not only avoid loading the whole data set in memory from the database, but also avoid scanning it entirely. In other words we needed some sort of indexed in-memory structure.
Enter go
The key features that made us choose Go for writing this new service were:
- Memory management: Go allows you to approach C-level performance when it comes to managing your data in memory, since we can have byte-level control of data structures.
- Parallelism: the Go runtime makes it very easy to implement parallel algorithms whose goroutines communicate via built-in synchronization primitives like channels and locks, leveraging multi-core hardware.
Both these aspects are problematic in stock Python, because of the lack of support for “low-level” data structures with tight memory layout and because of the notorious issues with the global interpreter lock (GIL) when running multiple threads of a CPU-intensive parallel algorithm.
Data structures
As mentioned, the basic idea behind the service is to keep all data in memory and organise it in a way that avoids full scans of the data set, essentially using some sort of indexing and aggregation. There are two main data structures that we implemented in this regard: a global table of cross-computer package reference counts and an index of per-computer package lists.
Global package reference counts
The global package reference counts provide an overview of the packages in a certain state across all your computers, not just across specific selections. For each possible package state (like “upgradable” or “installed”) we keep a table of reference counts that tells us which package names are in that state in at least one computer. For each package name, we also track which specific package IDs are in the given state somewhere in these computers, and how many computers are actually a “hit” for these package IDs (i.e. they have that package ID in the state associated with the structure). You can think of a package ID simply as an integer identifying a package with a certain name and a certain version, for instance package ID 3 could map to apache2 version 2.4.7-1, while package ID 1 could map to libc6 2.7.6-8.
For example:
| Package name | Package IDs | Number of computers |
| apache2 | 3,8,5 | 142 |
| libc6 | 1 | 3 |
| python2.7 | 6,4 | 49 |
| … | … | … |
Note that the rows in the data structure are ordered alphabetically, and the column with the number of computers is the reference count, not used in the search algorithm but fundamental for updating the table efficiently when the data changes (if the count gets down to 0 we remove the row).
Index of per-computer package lists
This second data structure is a simple index mapping a computer ID to an ordered array of package IDs that are in a certain status on that computer (for example “upgradable”).
| Computer ID | Package IDs |
| 3 | 6, 8 |
| 7 | 1, 6 |
| … | … |
The algorithm
Now, assume that the user has selected computers with IDs 4 and 9 and wants to be shown the first 25 package upgrades across these two computers. We start a linear scan of the global package reference counts table associated with upgrades: each package ID is a “candidate” hit, and for each of them we search if there’s actually a computer in the selection with that upgrade.
This scan allows us to build a “hit” data structure, similar to this one:
| Package name | Package IDs |
| apache2 | 8 |
| python2.7 | 6,4 |
| … | … |
and we would stop scanning when we reach 25 package names hits or we exhaust the global table.
Note that when we process a row in the global table, we essentially get a candidate package upgrade ID and start scanning the selection searching for it, computer by computer. Given that the list of package IDs per computer is sorted, that’s a fast binary search for each computer. Furthermore these per-computer searches can be performed in parallel on multi-core systems and we can stop searching when we find the first hit. At this point we know that our selection contains at least one computer with candidate package upgrade we are considering, and we can proceed to the next row in the global table.
If the global table is very big (e.g. you have 2,000 package upgrades across all your computers), in the worst case we have to scan it all in order to reach 25 hits or be able to tell that there are no more hits. However if the given selection is relatively small, the cost of scanning will be modest, while the larger the selection the bigger the probability is that we reach 25 hits early enough. So the worst case is actually very rare, in practice.
When we are done scanning the global table (either hitting the requested match limit or reaching the end of the table) we can then actually take the trouble to thoroughly check which computers have which packages, since at that point the data set won’t be very large, and we can feed the result to the UI, which can then easily render the screenshots shown at the beginning.
There are more sophisticated searches that we support (for example filtering not only by state, like “upgradable”, but also by package name or description), and also support for efficient pagination is there (“get me the next 25 hits”). These use cases require a bit more care and diligence, but the fundamental technique is the same.
Finally, there is obviously the problem of keeping this in-memory data up-to-date against the stream of package changes that computers constantly report. This mainly involves careful locking of data structures, plus merging and queuing up updates so we minimize the time that we hold such locks.
Benchmarks
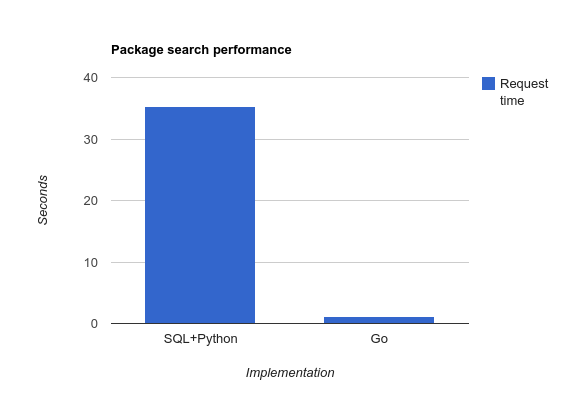
In a relatively small test on our hosted environment the difference in performance is dramatic: without this Go service the package listing page showing updates for 500 computers took 35.26 seconds to load (with a hot database cache), while with the service enabled it took only 1.13 seconds.
Managing thousands of Ubuntu machines as if they were one presents some interesting challenges. Designing solutions as lightweight as possible lets us keep pace with the super dense cloud world we live in.
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
Join Canonical at NVIDIA GTC 2025
Canonical, the company behind Ubuntu and the trusted source for open source software, is thrilled to announce its presence at NVIDIA GTC again this year. Join...
Install FreePBX and Asterisk on Ubuntu 24.04 LTS for security patches until 2036
Deploying FreePBX and Asterisk on a single Ubuntu virtual machine in a public cloud is an ideal solution for personal users and small to medium-sized...
Entra ID authentication on Ubuntu at scale with Landscape
Authd allows Entra ID authentication on both Ubuntu Desktop and Server. Learn how to configure Authd at scale using Landscape and Cloud-init