XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible and portable. It implements machine learning algorithms under the Gradient Boosting framework and provides a parallel tree boosting that solves many data science problems in a fast and accurate way.
Hyperparameter tuning is the process of optimizing the hyperparameter values to maximize the predictive accuracy of a model. It is a dark art in machine learning, the optimal parameters of a model can depend on many scenarios. So it is impossible to create a comprehensive guide for doing so. If you don’t use Katib or a similar system for hyperparameter tuning, you need to run many training jobs yourself, manually adjusting the hyperparameters to find the optimal values.
The steps to configure and run a hyperparameter tuning experiment in Katib are:
-
Package your training code in a Docker container image and make the image available in a registry.
-
Define the experiment in a YAML configuration file. The YAML file defines the range of potential values (the search space) for the parameters that you want to optimize, the objective metric to use when determining optimal values, the search algorithm to use during optimization, and other configurations.
-
Run the experiment from the Katib UI, either by supplying the entire YAML file containing the configuration for the experiment or by entering the configuration values into the form.
As a reference, you can use the YAML file of the fpga xgboost example.

Source: http://ufldl.stanford.edu/housenumbers
SVHN is a real-world image dataset obtained from house numbers in Google Street View images. It can be seen as similar in flavor to MNIST (e.g., 32-by-32 images centered around a single digit), but incorporates an order of magnitude more labeled data (over 600,000 digit images) and comes from a significantly harder, unsolved, real world problem (recognizing digits and numbers in natural scene images).
Click NEW EXPERIMENT on the Katib home page. You should be able to view tabs offering you the following options:
-
Metadata. The experiment code name, e.g. xgb-svhn-fpga.
-
Trial Thresholds. Use the Parallel Trials to limit the number of hyperparameter sets that Katib should train in parallel.
-
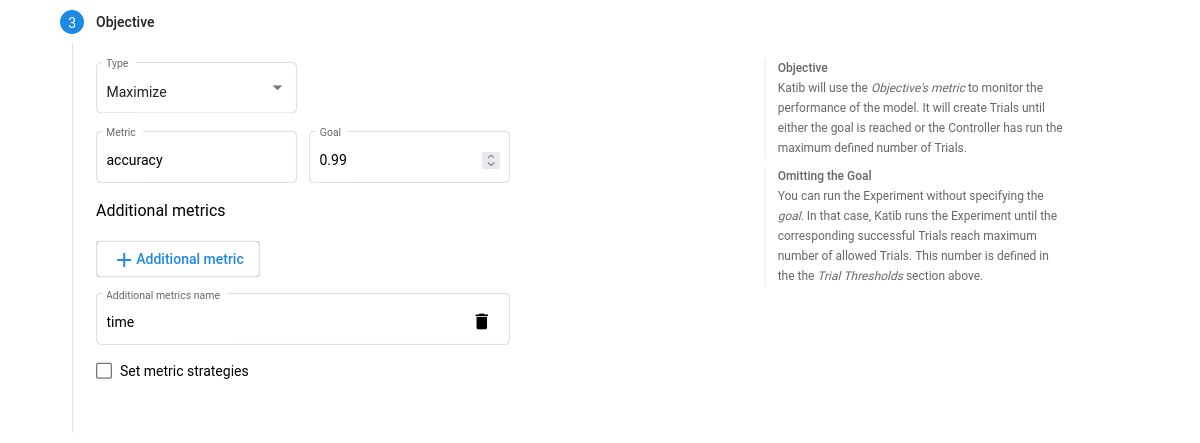
Objective. The metric that you want to optimize. A common objective is to maximize the model’s accuracy in the validation pass of the training job. Use the Additional metrics to monitor how the hyperparameters work with the model (e.g. if/how they affect the train time).
-
Hyper Parameters. The range of potential values (the search space) for the parameters that you want to optimize. In this section, you define the name and the distribution of every hyperparameter that you need to search. For example, you may provide a minimum and maximum value or a list of allowed values for each hyperparameter. Katib generates hyperparameter combinations in the range.
-
Trial Template. The template that defines the trial. You have to package your ML training code into a Docker image, as described above. Your training container can receive hyperparameters as command-line arguments or as environment variables.
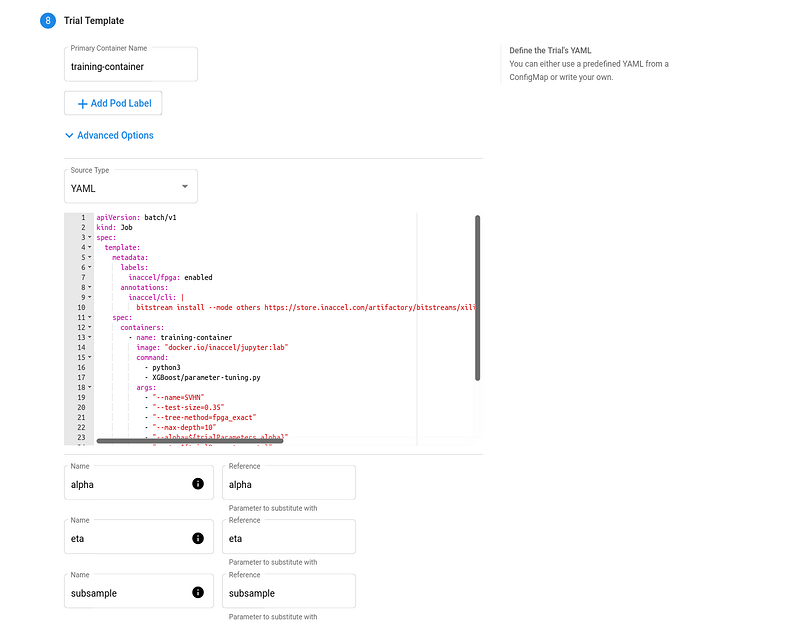
-
FPGA accelerated Trial Job:
apiVersion: batch/v1
kind: Job
spec:
template:
metadata:
labels:
inaccel/fpga: enabled
annotations:
inaccel/cli: |
bitstream install --mode others https://store.inaccel.com/artifactory/bitstreams/xilinx/aws-vu9p-f1/dynamic-shell/aws/com/inaccel/xgboost/0.1/2exact
spec:
containers:
- name: training-container
image: "docker.io/inaccel/jupyter:lab"
command:
- python3
- XGBoost/parameter-tuning.py
args:
- "--name=SVHN"
- "--test-size=0.35"
- "--tree-method=fpga_exact"
- "--max-depth=10"
- "--alpha=${trialParameters.alpha}"
- "--eta=${trialParameters.eta}"
- "--subsample=${trialParameters.subsample}"
resources:
limits:
xilinx/aws-vu9p-f1: 1
restartPolicy: Never
-
CPU-only Trial Job:
apiVersion: batch/v1
kind: Job
spec:
template:
spec:
containers:
- name: training-container
image: "docker.io/inaccel/jupyter:lab"
command:
- python3
- XGBoost/parameter-tuning.py
args:
- "--name=SVHN"
- "--test-size=0.35"
- "--max-depth=10"
- "--alpha=${trialParameters.alpha}"
- "--eta=${trialParameters.eta}"
- "--subsample=${trialParameters.subsample}"
restartPolicy: Never
-
Open the Katib UI as described previously.
-
You should be able to view your list of experiments. Click the name of the XGBoost SVHN experiment.
-
There should be a graph showing the level of validation accuracy and train time for various combinations of the hyperparameter values (alpha, eta, and subsample):
Comparing the FPGA accelerated experiment with the equivalent CPU-only one, you will notice that the accuracy of the best model is similar in both implementations.
However, the performance of the 8-core Intel Xeon CPU of the AWS F1 instance is significantly (~6 times) worse than its single (1) Xilinx VU9P FPGA, in this XGBoost model training use case.