
Scaling out ubuntu.com for 16.04 release

Tom Haddon
on 6 June 2016
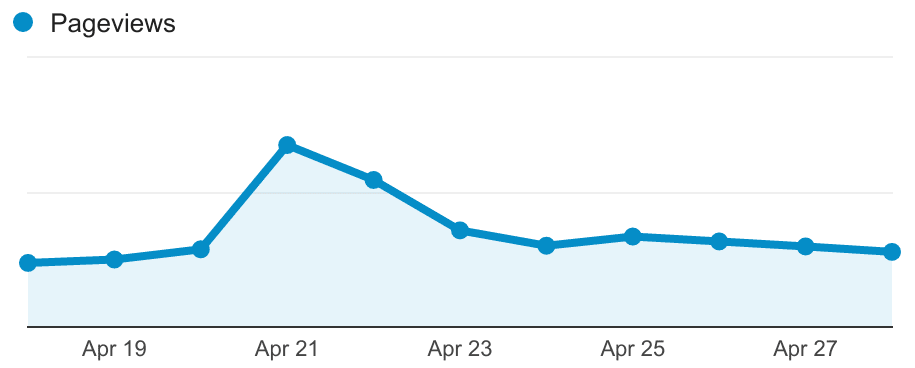
On release day for Ubuntu, the amount of traffic to ubuntu.com increases significantly. Comparing the amount of hits the website received on release day for 16.04 in comparison to the same day the previous week, we saw the number of requests grow by 209% over the 24 hour period. Looking at a particular hour around the time of release itself, the growth is even more pronounced – from 17:00 UTC to 18:00 UTC comparing release day with the week before, we saw the number of requests grow by 326%.
From previous releases, we knew to expect a growth in traffic, and knew we need to expand capacity to do so. So how did we do that?
The service itself runs on an OpenStack cloud we run for production services, is deployed via Juju and managed with Mojo. So all that was needed was:
juju add-unit webapp -n 4
mojo run --manifest manifest-verifyThe first command simply adds four more units/virtual machines to the webapp service. Juju does this by asking OpenStack for four new instances. Once they’ve spun up, Juju then deploys the application server onto these units.
It also deploys any subordinate services we’ve configured as associated with this service, including Landscape for package updates and monitoring, Nagios for alerting and a subordinate charm to upload access logs to Swift for permanent storage.
Furthermore, because the webapp service has a relation with a load balancing service in the same environment (in this case, HAProxy), Juju configures HAProxy to add these new webapp units into its load balancing set.
So with one simple command we’ve scaled out our service to be able to cope with the extra release day traffic.
We use Mojo to manage the service, so the second command allows us to verify the changes we’ve made. It starts by confirming Juju has finished making any changes to the environment (i.e. adding the new webapp units and configuring them in HAProxy), and that Juju status is not reporting any errors. It then connects to every server in the service, and runs all the Nagios checks on them. These checks confirm the webapp service is working as expected, and that HAProxy is reporting all of the instances as live.
And once traffic subsides to normal levels, scaling in is easy too. Let’s say the units you added above were added as webapp/9, webapp/10, webapp/11 and webapp/12 as machine 13, 14, 15 and 16:
juju remove-unit webapp/9 webapp/10 webapp/11 webapp/12
juju remove-machine 13 14 15 16
mojo run --manifest manifest-verifyWhat about testing?
That’s all fine and good, but how did we know it was going to work as expected? Surely we didn’t just run this directly on production without any kind of testing? Well, I’m glad you asked that, as it lets me explain a little about our approach to DevOps and continuous integration testing.
As mentioned above, we deploy our production services on OpenStack using Juju and Mojo. The combination of these tools give us an entirely repeatable service set up that can be easily replicated. We use this to do two things.
The first is that we give developers an account on our production OpenStack instance, and let them deploy and manage staging versions of their services. This means they get operational experience with their own services, but also that they can use it to test changes to the service before asking us to make those same changes in production. Because Mojo’s specifications are revision controlled we can be sure that the changes made in one environment are the same ones being made in another environment.
So before scaling out the webapp service on production as above, we asked the developers to test this for us on staging to confirm it worked as expected. This gave us the confidence we needed to know that we could simply run “juju add-unit” and the service would scale out as intended.
The second thing we do as a result of having a repeatable service deployment story is to use it with continuous integration. We have Jenkins jobs confirming that as changes are made to our Mojo specifications we can still deploy a service from scratch if we need to at any point, as well as doing automated deployments of code or content updates for some services.
We do this by deploying the exact same version of code or content as is currently on production, and then testing an update to a specified version. If that works as expected, developers can then kick off a production update themselves to that tested version. In this exact manner, the web team had full control over the timing of the update of content on ubuntu.com for the 16.04 release, and were able to deploy whenever they saw fit.
If you want to start deploying charms for yourself head over to jujucharms.com or if you’re interested in finding out how Canonical can help you manage your OpenStack cloud talk to us about BootStack.
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
How to avoid package End of Life through backporting
When a Git vulnerability hit systems past Ubuntu package end of life, teams had to reassess security options. Learn how to stay protected beyond standard support.
Showcasing open design in action: Loughborough University design students explore open source projects
Last year, we collaborated with two design student teams from Loughborough University in the UK. These students were challenged to work on open source project...
Canonical Ubuntu and Ubuntu Pro now available on AWS European Sovereign Cloud
Canonical announced it is a launch partner for the AWS European Sovereign Cloud, with Ubuntu and Ubuntu Pro now available. This new independent cloud for...